Printing crosswords
I spent hours implementing a replacement print layout for a free crossword so that I could save myself several seconds every day.
We used to pick up the free Evening Standard every day and do the (fairly easy) cryptic crossword over a cup of tea before cooking dinner.
Now that the physical paper is hard to get hold of, I’ve been printing off the online version of the crossword instead. It’s better than nothing, but the layout has some flaws: the clues often overlap the bottom of the grid, the grid for the larger Friday crossword is unreadably tiny, it makes bad use of the space on the page, and it just generally looks a bit unappealing:

Most annoyingly, it takes about six steps to get from opening the website to printing a crossword.
After several months of this, and with a gloomy day free, I finally decided to do something about it.
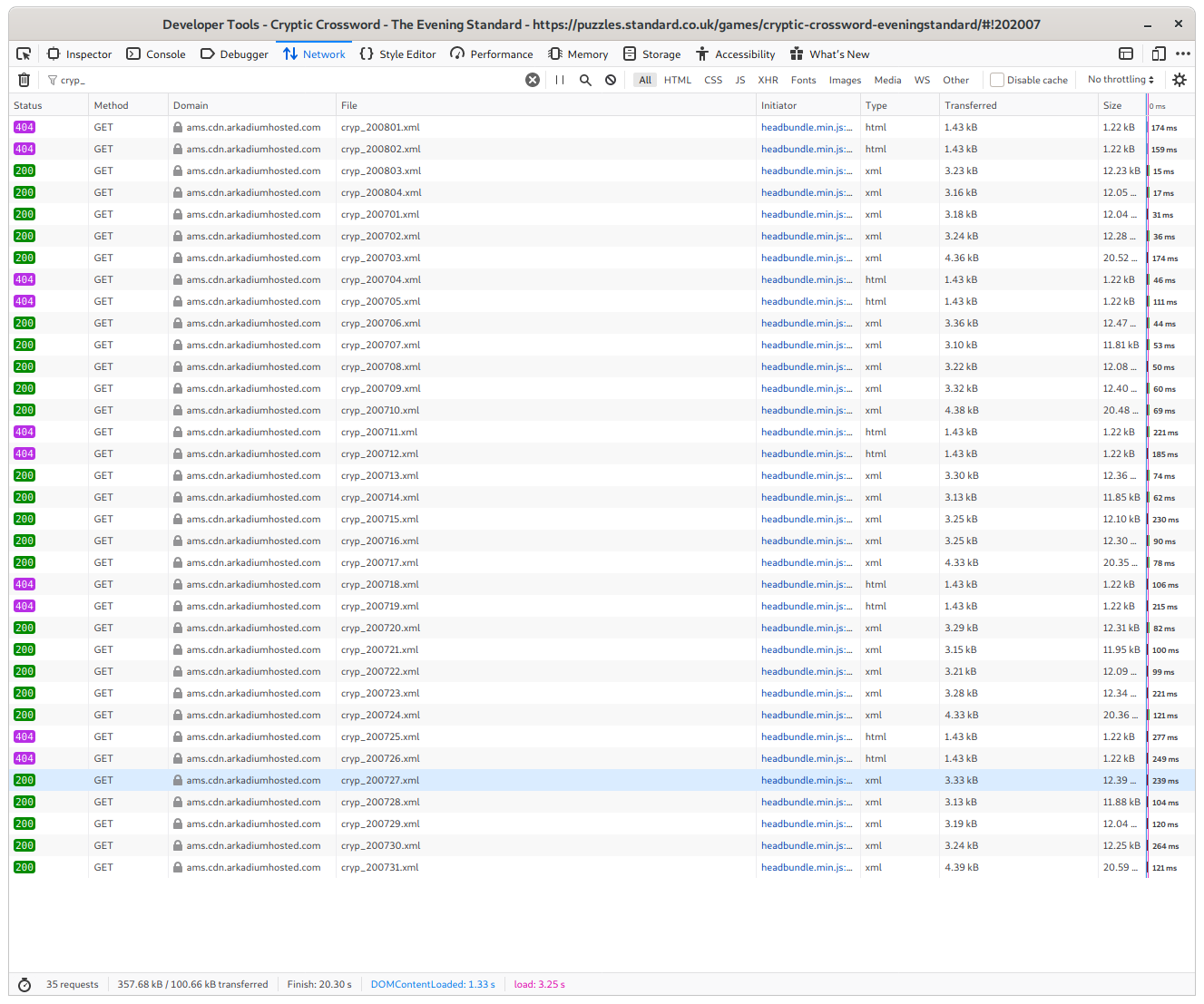
With the aid of the Web Developer tools, it’s quite obvious where the data comes
from: there’s an XML file for each day’s crossword named cryp_YYMMDD.xml. The
naïve front-end implementation merely iterates through every possible date from
the start of the month. If the URL for a day returns a 404 Not Found, there’s no
crossword for that day:
The XML is fairly self-explanatory. There’s a crossword containing a grid in
which there are cells that are either a block, a letter, or a letter with a
clue number. We can ignore the presentational stuff about cell and divider size:
<crossword>
<grid width="19" height="19">
<grid-look numbering-scheme="normal" cell-size-in-pixels="26" clue-square-divider-width="0.7"/>
<cell x="1" y="1" type="block"/>
<cell x="1" y="2" type="block"/>
<cell x="1" y="3" solution="D" number="10"/>
<cell x="1" y="4" solution="A" number="13"/>
<cell x="1" y="5" solution="P"/>
<cell x="1" y="6" solution="P" number="16"/>
<cell x="1" y="7" solution="E"/>
...
After that, there’s a section of words that links sequences of cells but is
unnecessary for a non-interactive implementation.
Then there are clues blocks, one for each direction, each of which contains
individual clues:
<clues ordering="normal">
<title>
<b>Across</b>
</title>
<clue word="1" number="8" format="5,2">Be rebuked for giving a pet to the young girl</clue>
<clue word="2" number="9" format="2,3,4">Going off then to pack a kind of vase</clue>
<clue word="3" number="13" format="5">A commotion that gets you up</clue>
...
And at the top of each file, we get a hint about where they came from:
<?xml version="1.0" encoding="UTF-8"?>
<crossword-compiler xmlns="http://crossword.info/xml/crossword-compiler">
<rectangular-puzzle xmlns="http://crossword.info/xml/rectangular-puzzle"
alphabet="ABCDEFGHIJKLMNOPQRSTUVWXYZ">
...
Crossword Compiler for Windows. I could just buy a copy of that, probably, and print directly. Except for the Windows part. And I bet there would still be a lot of clicking around.
I want a more automated solution.
So I made one. Now, all I have to do is to type
fetch-crossword -p
And today’s crossword will come out of my laser printer a few seconds later, looking something like this:

Much nicer, I think. I’ve retained the original implementation’s toner-friendly technique of using a shade of grey for the blocked cells.
There’s not much to the implementation:
- The XML file is downloaded from its predictable URL.
- The Crossword Compiler XML is parsed into a simpler intermediate structure.
- This is converted into a TeX document.
- Everything is passed through xelatex using the crossword LaTeX package.
It’s mostly glue between existing libraries for XML parsing, TeX escaping,
crossword rendering, shelling out to xelatex, and sending a PDF file to the
printer.