An accessible timetable for Thames Clippers
I’ve been playing around with ways to obtain schedule information for the Thames Clippers service. As a side-effect, I’ve made a more accessible HTML version of their PDF timetable.
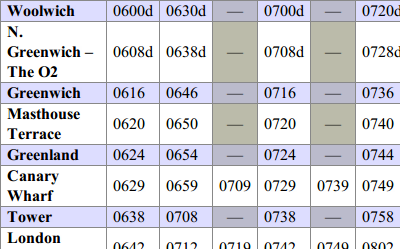
As I’ve probably mentioned before, the Thames Clippers river boat service serves a pier at the end of my street—I can see it from my window, in fact. It’s not the most convenient way to travel—it serves a limited number of destinations by definition—but it’s one of the most pleasant.
I’ve been looking at their timetable data because there are a few interesting things I want to do with it. I’d like to display the time of the next departure as a widget on my computer screen, for example. I’d also like to have a way to check the times from my mobile phone.
I’m limited in this by the fact that the timetable is published only as a PDF. All PDFs tell you is what the text looks like and where it is on the page. The semantic meaning of the text—of what it is, and how it relates to other text—is lost. (This is, incidentally, one of the reasons why it’s important that government data is released in better-structured formats than PDF.)
I did a bit of a feasibility study, and settled on using
pdftotext to extract the tables. With the
-layout option, it lines up the data more or less as
it appears on the page. I also wrote a reusable library to
handle reconstructing the tabular text back into columns.
The easiest way to be able to check my output was to transform it into HTML. And once I’d done that, I now had an accessible version of the timetable which was already a lot more useful than having the information locked in a PDF. So I gave it a lick of CSS, and stuck it on the internet:
Accessible Thames Clippers Timetable
It’s done in HTML5 with CSS3. If you’re using a rubbish browser, it should still look OK, but it won’t have the nice zebra stripes, for example.
I’ve put the code used to generate it on Github, along with a brief explanation of how to use it.
I fully expect someone to take umbrage. No good deed goes unpunished, and all that.