Speeding up a random query
(Warning: this post contains extensive discussion of SQL. Persons of a nervous disposition should exercise caution.)
We—or rather, a couple of colleagues; I was working on something else—released a new reevoo.com homepage yesterday. I’m sure that there will be plenty of tweaks still to come, but it’s a definite improvement over the previous one in that it gives you an idea of what Reevoo actually is, solving an issue that came up in usability testing a few weeks ago.
Although there isn’t anything obviously complex about the new home page, that’s a little deceptive: it actually relies on a several database queries, one of which is a fairly complex query to find a random handful of product categories that satisfy a number of conditions.
Unfortunately, all these queries were making the home page really slow: it was taking five seconds to load. Not only is that unacceptably slow by modern website standards, it also means that server and database throughput was lower than it should be. That’s not anyone’s fault, though: we took the decision to make it work first, then to make it efficient.
So my task this morning was to speed it up.
I started by looking at the query logs, and was able to find a particularly low-hanging fruit: a SELECT statement that was being executed for each product in a category when we only needed the first result. Getting rid of all those extraneous queries cut the load time almost in half.
After that, the slowest query was a complex one joining five data models over six tables. Although it was only called once, it took 0.9 seconds to run.
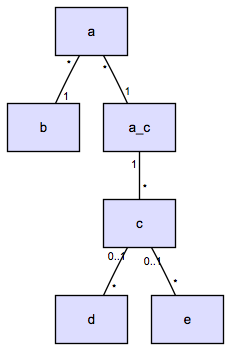
Here’s a diagrammatic representation of the relationships
between the models in question. (I’ve anonymised the table names.)
There are five models, A to E, and one additional table,
a_c, for the many-to-many relationship between A and
C:
This is the original SQL query:
SELECT a.* FROM a INNER JOIN b ON b.id = a.b_id INNER JOIN a_c ON a_c.a_id = a.id INNER JOIN c ON c.id = a_c.c_id INNER JOIN d ON d.c_id = c.id INNER JOIN e ON e.c_id = c.id WHERE b.name = 'foo' AND a.value NOT LIKE 'bar%' AND a.value NOT LIKE 'baz%' ORDER BY RAND() LIMIT 21
(Why 21? Well, an easy way to get a decent spread of items is to
ask for a random selection of more than you need, and to throw away
ones that look too much like ones you’ve already picked. If you’ve
checked all the candidates and still need some more, you can call
the query again. It’s a trade-off that lets you keep most of the
business logic in the application but without too much of a
performance penalty from ploughing through large data sets. The
trick is to set the LIMIT to a value that gives you
enough data most of the time.)
The thing that makes it so slow is the ORDER BY
RAND() at the end: in order to sort the results randomly,
the database (MySQL) must first determine what they are, and then
sort them. Random ordering on a single table isn’t a problem, but
when it’s the result of a complex query with multiple joins, it is.
Take out the ORDER and the query is fast—but then it’s
not random any longer. We want random.
My first idea was to move the randomisation to somewhere where
it wouldn’t do so much damage. I tried replacing the join on
a_c with a subquery that returned the same data
ordered randomly:
SELECT a.* FROM a INNER JOIN b ON b.id = a.b_id INNER JOIN ( SELECT * FROM a_c ORDER BY RAND() ) AS a_c_2 ON a_c_2.a_id = a.id INNER JOIN c ON c.id = a_c_2.c_id INNER JOIN d ON d.c_id = c.id INNER JOIN e ON e.c_id = c.id WHERE b.name = 'foo' AND a.value NOT LIKE 'bar%' AND a.value NOT LIKE 'baz%' LIMIT 21
This was much faster, taking about 0.04 seconds (much better
than the previous 0.9). It wasn’t truly random, though: the values
came back clustered by a.value, for reasons that
weren’t surprising once I’d thought about it. This meant that the
query ended up being called several times from the application
code, negating much of the speed improvement.
However, all wasn’t lost: it was a good start. If I applied the same principle, randomising where it’s cheap, and then cut down the search set, I could still order the whole result set randomly. So that’s what I did:
SELECT a.* FROM a INNER JOIN b ON b.id = a.b_id INNER JOIN ( SELECT * FROM a_c ORDER BY RAND() LIMIT 1000 ) AS a_c_2 ON a_c_2.a_id = a.id INNER JOIN c ON c.id = a_c_2.c_id INNER JOIN d ON d.c_id = c.id INNER JOIN e ON e.c_id = c.id WHERE b.name = 'foo' AND a.value NOT LIKE 'bar%' AND a.value NOT LIKE 'baz%' ORDER BY RAND() LIMIT 21
The 1000 limit was chosen empirically as a number that provided a good spread of results most of the time, without being large enough to slow down the query.
This query still returns in under 0.05 seconds, and gives results as good as the original slow query it replaced.
Finally, I added an index on the two foreign key fields of a many-to-many join table to speed up another slow query.
After all that, the page took now loads in half a second. That’s an order of magnitude faster, and a satisfactory result.