Rerouting Rails
One of the things I talked about recently was the routing in Ruby on Rails. Simply put, it’s horrible. I mean, it’s clever, but it’s a long way from being either clear or elegant. Rather like the Dark Side, metaprogramming is seductive—but it’s rarely the right solution to an algorithmic problem. There’s a lot of code generation in the routing code, and it’s very hard to follow. Not impossible, but hard.
You might ask why it matters, given that it works as it is now. For me, the most important reason is that it’s inelegant. Although my initial revulsion is aesthetic, inelegance hides a lot of problems, because code that’s hard to read is code that’s hard to analyse, improve, and debug.
Significantly, the recent security vulnerability in Rails was related to routing, which is a good reason to look at it with a critical eye.
Jamis Buck has written a few articles explaining routing, covering the DSL itself, route recognition, and route generation. They give an insight into how and why it works.
But I still think it could be implemented better, so I stayed up late last night and started to implement a tree-based routing system. I’m not sure if this is the best kind of tree to use, but I think it’s the step in the right direction.
So far, I’ve done the tree building and forward matching of routes. Recognising a route is very easy once you’ve built the tree: you just walk the tree starting at the root node for each segment of the path, choosing the leftmost matching node each time. Including parsing the routes definition itself, it’s only a couple of hundred lines.
With a little extra code, it’s also easy to throw the tree into Graphviz, which makes it a lot easier to visualise. Here’s an example tree diagram, using the routes file from Radiant CMS.
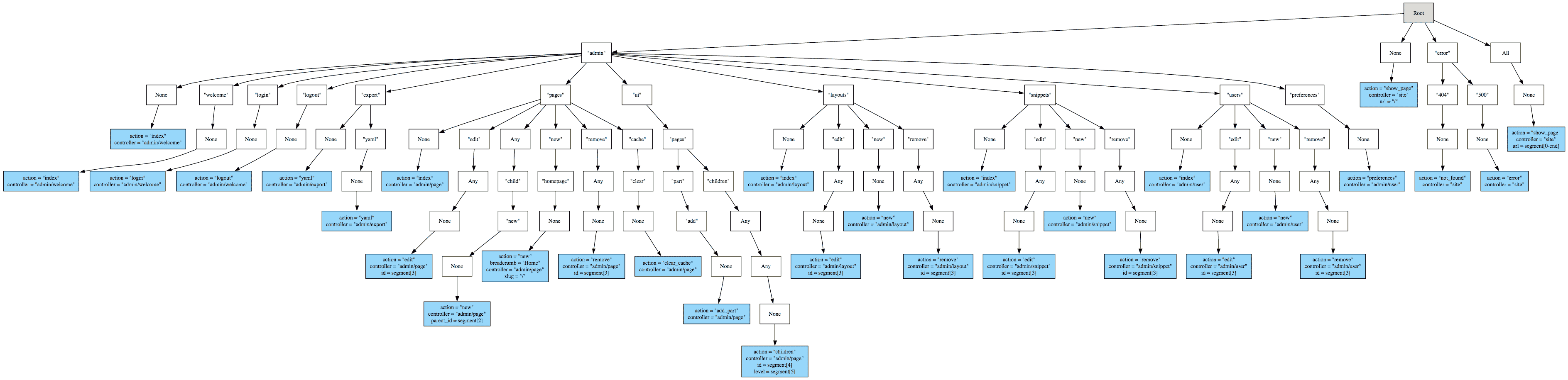
Next, I’ll implement route generation—I have a few ideas about that—and compare the performance with the current Rails routing code. Then, maybe, I’ll start to look at optimisation.