Archive: 2006-06
Fixing invalid UTF-8 in Ruby, revisited
When working with UTF-8-encoded text from an untrusted source like a web form, it’s a good idea to fix any invalid byte sequences at the first stage, to avoid breaking later processing steps that depend on valid input.
I love the World Cup
Not for the sport, mind you. There are many things I’d rather do than spend two hours watching men kicking a ball. As a spectacle it bores me, and I don’t have the depth of feeling to participate in the tribal side of supporting.
Six six six
Today’s date reminds me of a true story. Many years ago—I think I must have been thirteen at the time—we spent a maths class at school on statistics. We were organised into pairs, and each pair had three dice. We too it in turns to throw the dice and note the results.
Broken algorithm, or broken language?
There’s an article on the official Google Research blog asserting that ‘nearly all binary searches … are broken’. What’s really interesting about it is that it’s not the algorithm that is broken, per se.
Fixing a major TextMate annoyance
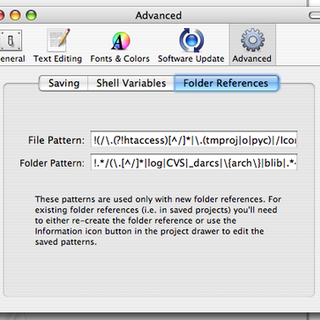
The Reevoo office is all-Mac, with the exception of one bargain-basement Windows XP box used for billing and debugging our website in Internet Explorer (to which, as regular readers will know, I bear an intense and righteous anger, but that’s not what I want to talk about today). We developers use TextMate as an editor. It’s a decent product with some well-thought-out features that really increase productivity, but it’s also hopelessly immature in many ways. In general, although I miss vim key mappings, I’m happy using TextMate for daily work.